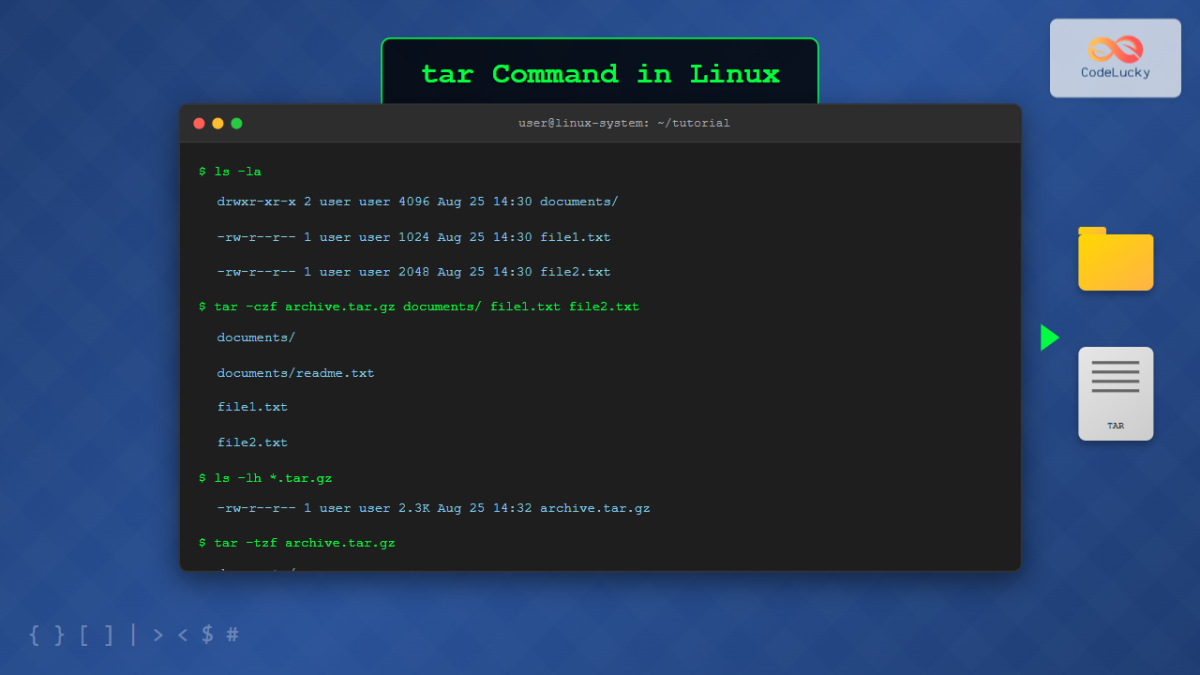
Ho visto un sistemista junior distruggere un intero ambiente di staging perché pensava che dare un comando veloce bastasse a spostare una configurazione complessa. Mancavano i permessi, i link simbolici erano saltati e metà dei file nascosti non erano stati inclusi. Quell'errore è costato quattro ore di downtime e una notte insonne per ricostruire i permessi a mano. Il problema non è lo strumento in sé, ma l'eccessiva sicurezza di chi pensa che Zipping A Directory In Linux sia un'operazione banale da manuale della prima settimana. Se non stai attento ai dettagli del filesystem, quello che ottieni è solo un archivio rotto che sembra funzionare finché non provi a ripristinarlo su un altro server.
Il disastro dei permessi e la pigrizia del comando base
L'errore più comune che vedo fare costantemente è lanciare un comando generico senza considerare chi possiede i file. Se comprimi una cartella che contiene file di diversi utenti o servizi (pensa a una directory web con file di root e file dell'utente www-data) e lo fai senza le opzioni corrette, rischi di appiattire tutto sotto il tuo utente attuale. Quando scompatterai quell'archivio su una nuova macchina, il server web non riuscirà a leggere i file o, peggio, non avrà i permessi di scrittura sulle directory temporanee. Ho visto aziende perdere migliaia di euro in consulenze d'emergenza solo perché il database non riusciva più a scrivere nei propri log dopo un trasferimento maldestro.
La soluzione non è solo eseguire il comando, ma assicurarsi di preservare gli attributi. Non puoi sperare che il sistema indovini le tue intenzioni. Devi forzare l'inclusione di ogni bit di informazione sui permessi originali. Se non lo fai, stai solo creando una bomba a orologeria. Molti pensano che basti aggiungere un flag a caso, ma la verità è che se il filesystem di destinazione è diverso (magari passi da Ext4 a un vecchio FAT32 o un sistema di rete), i tuoi permessi spariranno comunque. Devi sempre verificare la compatibilità del formato d'archivio con le caratteristiche del sistema operativo che dovrà ricevere i dati.
Zipping A Directory In Linux e la trappola dei link simbolici
Quando il collegamento diventa un vicolo cieco
I link simbolici sono il sistema nervoso di molte installazioni software. Spesso puntano a librerie specifiche o a configurazioni globali. Se sbagli l'approccio, ti ritrovi con un archivio che contiene il file di collegamento ma non il file reale, oppure, ancora peggio, l'archivio include una copia fisica del file invece del link, raddoppiando o triplicando lo spazio occupato inutilmente. Ho gestito un caso dove un archivio che doveva pesare 200 MB è arrivato a 4 GB solo perché il processo aveva seguito e copiato fisicamente ogni singolo link simbolico verso librerie di sistema pesanti.
Risolvere il riferimento circolare
Il trucco sta nel decidere prima se vuoi i dati o i puntatori. Se stai migrando un sito WordPress, vuoi che i link rimangano tali. Se stai facendo un backup per conservazione a lungo termine, forse preferisci avere i dati reali. Non c'è una via di mezzo sicura. Devi conoscere la struttura della tua cartella prima di agire. Se lanci il comando alla cieca su una directory con link ricorsivi, potresti finire per riempire il disco prima ancora che l'operazione sia completata al 10% e mandare in crash l'intero server per mancanza di spazio.
L'illusione della compressione massima su file già compressi
Spesso vedo persone perdere ore cercando di ottenere il file più piccolo possibile usando algoritmi pesanti su directory piene di immagini JPEG, video o file PDF. È una perdita di tempo totale. Questi file sono già compressi alla fonte. Cercare di comprimerli ulteriormente con livelli di intensità elevati consuma solo cicli di CPU e memoria RAM, senza ridurre il peso finale di più dell'uno o due percento. In un ambiente di produzione, occupare il 100% della CPU per trenta minuti solo per risparmiare 5 MB su un archivio da 5 GB è una scelta folle che rallenta tutti gli altri servizi attivi sul server.
Nella pratica quotidiana, il tempo è più prezioso dello spazio su disco. Se hai fretta, usa un metodo veloce. Se hai spazio infinito ma poca banda, allora ha senso spingere sulla compressione, ma solo se i dati lo permettono. Se la tua directory contiene file di testo, log giganti o database SQL dump, allora la compressione aggressiva ti salverà la vita. Ma se stai lavorando con file multimediali, accetta la realtà: l'archivio peserà quasi quanto la cartella originale. Non sprecare risorse aziendali per un guadagno invisibile.
Confronto tra l'approccio amatoriale e quello professionale
Per capire davvero la differenza, guardiamo come si comporta chi non ha esperienza rispetto a chi ha passato anni nei data center.
Immagina di dover spostare una directory di configurazione di un server mail. L'amatore entra nella cartella superiore e scrive un comando semplice, magari dimenticando i file nascosti (quelli che iniziano con il punto) perché non li vede con un normale comando di elenco. Crea l'archivio, lo sposta sul nuovo server e lo scompatta. Risultato: il servizio non parte. Perché? Perché i file .htaccess o .env sono rimasti sul vecchio server, i permessi di esecuzione sugli script sono andati perduti e i link verso i certificati SSL puntano al vuoto. Ha risparmiato due minuti di digitazione per perdere tre ore di debugging.
Il professionista, invece, agisce diversamente. Prima di tutto verifica lo spazio disponibile. Poi usa una sintassi che include esplicitamente la ricorsività e la conservazione dei permessi. Non si fida della directory corrente, ma specifica percorsi assoluti o si assicura di essere nella posizione corretta per non includere strutture di cartelle inutili all'interno dell'archivio. Soprattutto, testa l'integrità dell'archivio appena creato prima di cancellare l'originale o chiudere la connessione. Sa che un archivio corrotto è peggio di nessun archivio, perché ti dà un falso senso di sicurezza finché non è troppo tardi per rimediare.
Gestire i file enormi che bloccano il sistema
Quando la directory supera i 50 o 100 GB, la gestione cambia radicalmente. Non puoi più permetterti di creare un unico file gigante se devi trasferirlo via rete o caricarlo su un servizio cloud con limiti di dimensione. Ho visto trasferimenti fallire al 99% dopo dieci ore di upload perché la connessione è saltata e il file era troppo grande per essere ripreso. In questi casi, devi dividere l'output in parti più piccole, gestibili e verificabili singolarmente.
- Dividi sempre i file sopra i 2 GB se devi spostarli su sistemi vecchi.
- Usa checksum (come MD5 o SHA256) per ogni singola parte.
- Assicurati di avere almeno il doppio dello spazio libero su disco prima di iniziare.
Se il tuo disco è pieno all'80%, provare a creare un archivio della cartella più grande fallirà miseramente, lasciandoti con un file temporaneo enorme che blocca il sistema e impedisce ai log di scriversi, causando potenzialmente il crash di servizi vitali come il database. È un errore da principianti che ha abbattuto server di produzione di alto livello.
La sicurezza dei dati e la crittografia mal gestita
Non puoi limitarti a raggruppare i file se dentro ci sono chiavi private, password o dati dei clienti protetti dal GDPR. Molti pensano che aggiungere una password veloce all'archivio sia sufficiente. Non lo è. Se usi algoritmi di cifratura obsoleti, un malintenzionato può forzare la protezione in pochi minuti con strumenti standard. Inoltre, se metti una password ma lasci i nomi dei file visibili nell'indice dell'archivio, stai comunque regalando informazioni preziose su come è strutturato il tuo sistema.
La crittografia seria richiede che anche l'elenco dei file sia nascosto. Ma attenzione: ogni volta che aggiungi uno strato di sicurezza, aumenti il rischio di perdere tutto se dimentichi la chiave o se il software di destinazione non supporta quel tipo specifico di protezione. Ho visto amministratori di sistema bloccare i propri backup dietro chiavi che non erano state documentate, rendendo i dati irrecuperabili proprio nel momento del bisogno. La sicurezza deve essere bilanciata con l'accessibilità documentata per chi ha il diritto di accedere a quei dati.
Uso consapevole di Zipping A Directory In Linux per l'automazione
Quando inserisci queste operazioni in uno script cron per i backup notturni, devi gestire gli errori in modo silenzioso ma efficace. Uno script che fallisce e non avvisa nessuno è un cancro silenzioso nella tua infrastruttura. Se il processo di creazione dell'archivio incontra un file che non può leggere perché è bloccato da un altro processo, lo script deve decidere se saltarlo e andare avanti o fermarsi e mandare un alert critico.
- Reindirizza sempre l'output di errore su un file di log dedicato.
- Controlla il codice di uscita del comando prima di procedere con la fase successiva dello script.
- Implementa una rotazione degli archivi per non saturare il disco nel tempo.
Non scrivere mai uno script che sovrascrive il backup del giorno precedente senza prima aver verificato che quello nuovo sia stato creato con successo. Se lo fai, prima o poi ti ritroverai con un file da 0 byte al posto del tuo unico backup, proprio il giorno in cui il server principale decide di rompersi. È una lezione che si impara sulla propria pelle, ma preferirei che la imparassi leggendo queste righe piuttosto che spiegando al tuo capo perché i dati dell'ultimo anno sono svaniti.
Controllo della realtà
Smettila di cercare il comando magico perfetto. Non esiste un modo unico e universale che funzioni per ogni scenario. Il successo in questo ambito dipende interamente dalla tua capacità di analizzare cosa c'è dentro quella cartella prima di toccarla. Se ci sono socket, pipe, file di device o strutture di filesystem virtuali (come /proc o /sys), i tuoi tentativi standard falliranno o produrranno spazzatura.
La realtà è che la maggior parte delle persone che lavorano su server moderni sottovaluta l'importanza della struttura del filesystem. Pensano che un file sia solo un nome e un contenuto, ma in ambiente enterprise, un file è un insieme di metadati, contesti di sicurezza (come SELinux) e relazioni con altri file. Se non rispetti questa complessità, i tuoi archivi saranno solo mucchi di bit inutilizzabili. Sii paranoico, controlla i tuoi backup e non dare mai per scontato che l'operazione sia andata a buon fine solo perché non hai visto messaggi d'errore immediati sulla shell. La competenza non sta nel conoscere a memoria tutti i flag, ma nel sapere cosa può andare storto e prepararsi di conseguenza.



