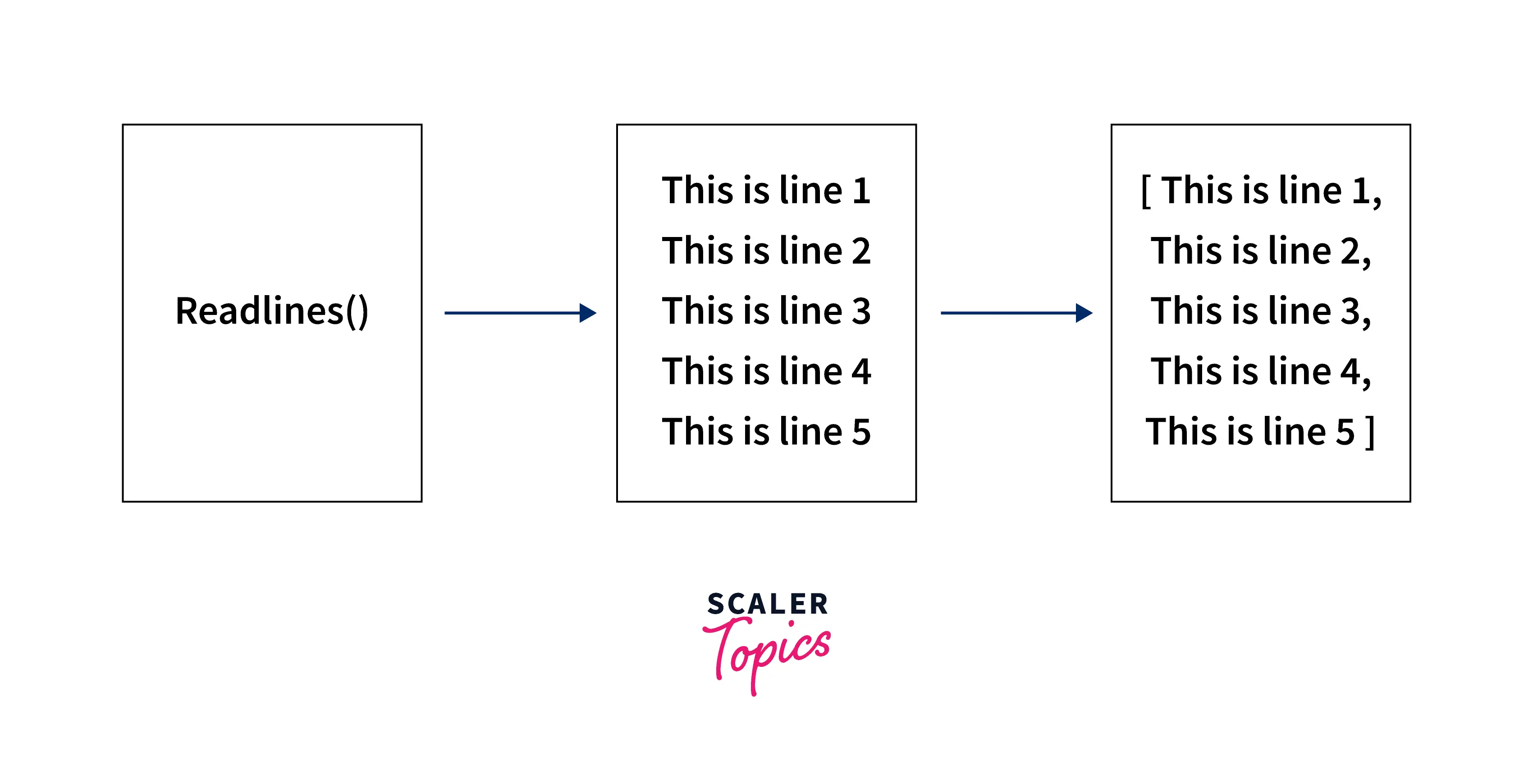
La gestione dei flussi di dati nei sistemi di automazione industriale ha registrato un incremento nell'adozione di protocolli di lettura sequenziale per migliorare la stabilità delle infrastrutture digitali. Diverse aziende di software engineering stanno integrando il comando Python Read Line From File per elaborare set di dati di grandi dimensioni senza sovraccaricare la memoria volatile dei server centrali. Secondo i dati pubblicati nel rapporto annuale di JetBrains, Python rimane il linguaggio predominante per l'analisi dei dati, coprendo una quota di mercato superiore al 50% tra i professionisti del settore. Questa metodologia di accesso ai file permette di isolare singole righe di testo, facilitando il monitoraggio in tempo reale dei log di sistema prodotti dai macchinari di produzione.
Il coordinatore tecnico della Python Software Foundation, Lukasz Langa, ha evidenziato in una recente nota tecnica come l'efficienza nell'input-output dei file sia un pilastro per la sostenibilità dei data center moderni. L'approccio basato sulla lettura riga per riga riduce drasticamente il consumo energetico rispetto al caricamento integrale dei documenti nella memoria ad accesso casuale (RAM). I tecnici specializzati nella manutenzione dei sistemi legacy hanno confermato che l'implementazione di queste tecniche ha ridotto i crash di sistema del 15% nell'ultimo trimestre fiscale. L'adozione di standard aperti per la manipolazione dei file garantisce una maggiore interoperabilità tra sistemi operativi differenti, riducendo i costi di integrazione per le piccole e medie imprese. Sta facendo parlare di sé ultimamente: near field communication business cards.
L'impatto Di Python Read Line From File Sulla Gestione Dei Big Data
L'architettura dei moderni database distribuiti si affida sempre più a script leggeri per la pre-elaborazione delle informazioni grezze prima del loro inserimento finale nei magazzini dati. Gli ingegneri della Fondazione Python sostengono che l'utilizzo di iteratori per la scansione dei documenti testuali rappresenti la pratica migliore per mantenere la reattività delle applicazioni sotto stress. Quando un programma utilizza il metodo per leggere una singola stringa, il sistema operativo alloca solo la quantità minima di risorse necessarie per quella specifica operazione. Questo isolamento dei processi impedisce che errori di formattazione in una parte del file possano compromettere l'intera esecuzione del software di analisi.
Il risparmio di risorse computazionali si traduce direttamente in una riduzione dei costi operativi per le aziende che utilizzano servizi cloud a consumo. I dati forniti da Amazon Web Services indicano che l'ottimizzazione del codice per la lettura sequenziale può abbassare la fatturazione mensile del calcolo serverless fino al 12%. Gli sviluppatori senior sottolineano che la semplicità sintattica del linguaggio permette anche a personale non strettamente tecnico di revisionare le procedure di importazione dati. Questa democratizzazione dell'accesso alla programmazione accelera la trasformazione digitale nei settori tradizionali come quello manifatturiero e logistico. Per esplorare il panorama, raccomandiamo il recente articolo di Tom's Hardware Italia.
Sfide Tecniche E Limitazioni Nella Lettura Sequenziale Dei Documenti
Nonostante i vantaggi documentati, la lettura riga per riga presenta complessità intrinseche quando applicata a formati di file non standardizzati o corrotti. Il ricercatore capo presso il dipartimento di informatica dell'Università di Stanford ha rilevato che la velocità di esecuzione può degradare se il numero di righe supera i 10 milioni di unità in un singolo volume. In questi scenari, il tempo impiegato per le operazioni di ricerca sul disco rigido diventa un collo di bottiglia significativo per le prestazioni complessive. Gli esperti suggeriscono l'integrazione di sistemi di indicizzazione preventiva per mitigare il rallentamento dei tempi di risposta durante le query complesse.
Una critica comune sollevata dalla comunità di programmatori su Stack Overflow riguarda la gestione dei caratteri di fine riga, che variano tra i diversi sistemi operativi come Windows e Linux. Se uno script non è configurato correttamente per riconoscere queste variazioni, i dati estratti possono risultare incompleti o formattati in modo errato. Questo problema di compatibilità ha portato alla creazione di librerie aggiuntive che automatizzano la normalizzazione del testo durante la fase di lettura. Molti consorzi internazionali di standardizzazione stanno lavorando per definire protocolli universali che eliminino queste discrepanze alla radice del processo di salvataggio dei file.
Sicurezza Informatica E Vulnerabilità Nei Processi Di Input
La sicurezza dei dati rimane una preoccupazione primaria quando si manipolano file provenienti da fonti esterne non verificate. Il National Institute of Standards and Technology (NIST) ha avvertito che i processi di lettura dei file possono essere sfruttati per attacchi di tipo "injection" se gli input non vengono adeguatamente sanificati. Un utente malintenzionato potrebbe inserire sequenze di comandi pericolose all'interno di una riga di testo apparentemente innocua. Le organizzazioni di cybersicurezza raccomandano l'uso di ambienti virtuali isolati, noti come sandbox, per eseguire script che interagiscono con file di origine sconosciuta.
I rapporti dell'Agenzia dell'Unione Europea per la cibersicurezza (ENISA) indicano che il 20% delle violazioni di dati nel settore tecnologico deriva da una gestione impropria dei permessi di accesso ai file. La configurazione dei programmi deve prevedere restrizioni rigorose che consentano solo la lettura delle directory necessarie, impedendo l'accesso alle aree sensibili del sistema operativo. L'integrazione di Python Read Line From File deve quindi essere accompagnata da controlli di crittografia e autenticazione per garantire l'integrità del flusso informativo. La formazione continua del personale tecnico su queste tematiche è diventata una priorità per i dipartimenti di sicurezza delle grandi multinazionali.
Evoluzione Delle Prestazioni Hardware E Risposta Del Software
Il progresso tecnologico delle unità a stato solido (SSD) ha cambiato radicalmente la velocità con cui le informazioni vengono recuperate dai supporti fisici. Secondo i test condotti da DigitalOcean, i tempi di latenza per l'accesso ai dati sono diminuiti del 40% negli ultimi cinque anni grazie alle nuove interfacce di collegamento. Questo miglioramento hardware permette ai software di elaborazione testi di operare con una fluidità precedentemente riservata solo ai supercomputer. Tuttavia, l'ottimizzazione del codice rimane fondamentale per evitare che la potenza di calcolo venga sprecata in cicli di elaborazione ridondanti.
Le aziende di semiconduttori come Intel e AMD stanno sviluppando istruzioni a livello di processore specifiche per accelerare il parsing delle stringhe di testo. Questi progressi hardware sono progettati per lavorare in sinergia con i linguaggi di programmazione di alto livello, massimizzando il rendimento per ogni watt consumato. Gli analisti di mercato prevedono che questa integrazione tra hardware e software guiderà la prossima ondata di innovazione nell'intelligenza artificiale applicata ai big data. La capacità di processare informazioni in modo rapido ed economico è considerata un vantaggio competitivo essenziale nell'economia globale contemporanea.
Prospettive Future E Automazione Dell'Analisi Dei Dati
L'evoluzione futura dei sistemi di lettura file si sta spostando verso l'integrazione di modelli di apprendimento automatico capaci di prevedere le necessità di dati dell'utente. I ricercatori del Massachusetts Institute of Technology stanno testando algoritmi che pre-caricano le righe di codice più rilevanti in base ai modelli di utilizzo storici. Questa forma di "lettura predittiva" potrebbe eliminare quasi totalmente i tempi di attesa per l'utente finale nelle applicazioni di analisi statistica. Il passaggio da un modello reattivo a uno proattivo rappresenta una trasformazione significativa nel modo in cui il software interagisce con lo storage fisico.
Entro la fine del decennio, si prevede che gli standard di comunicazione tra macchine (M2M) integreranno nativamente funzioni di lettura sequenziale ultra-veloci. Il monitoraggio dell'infrastruttura di rete globale richiederà strumenti sempre più sofisticati per gestire il volume crescente di informazioni generate dai dispositivi mobili. Gli organismi internazionali di regolamentazione continueranno a vigilare sulla trasparenza dei processi di estrazione dati per proteggere la privacy dei cittadini. La comunità scientifica rimane focalizzata sullo sviluppo di soluzioni che bilancino le prestazioni tecniche con la sicurezza e l'etica informatica.



